Azure Databricks & Apache Spark

Lakehouse Medallion Architecture
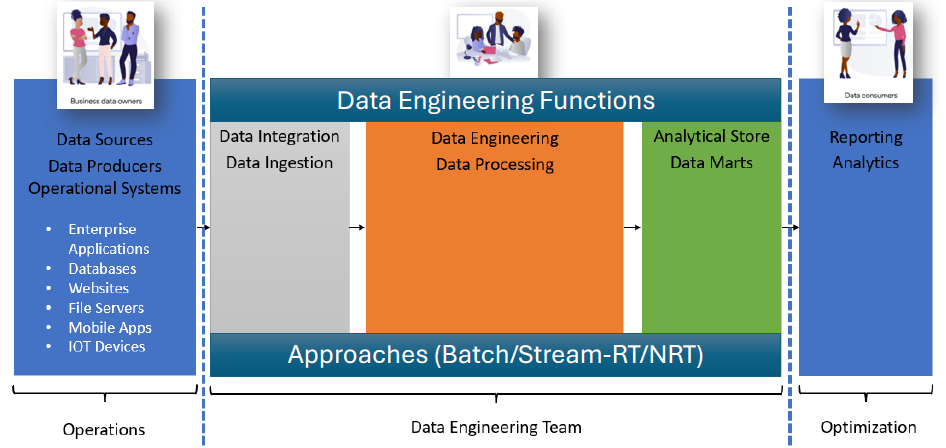
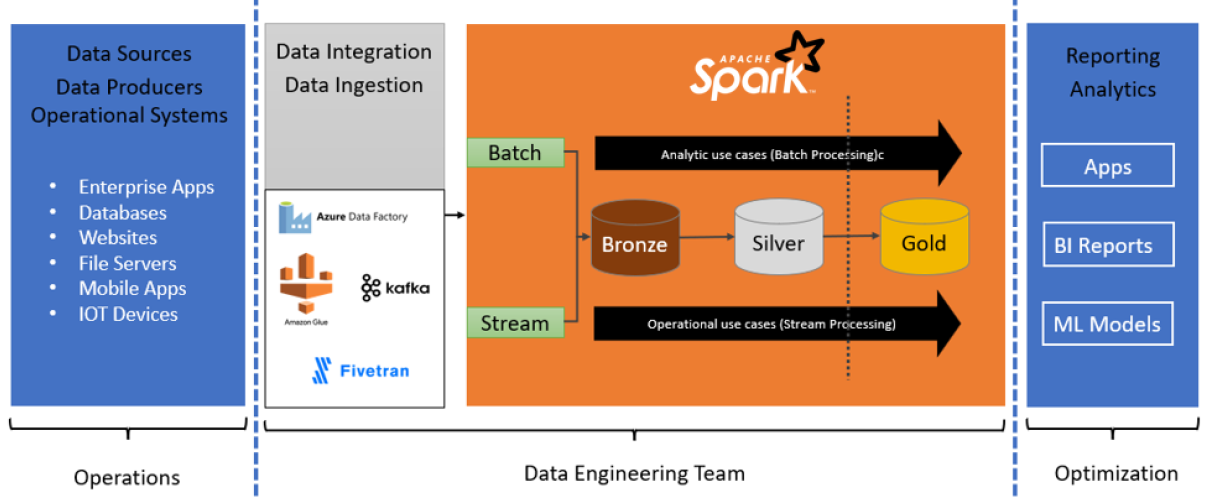
After Data ingestion/integration Build the system in layers with 3 minimum layers
Data Collection/Ingestion
Batch Mode: Collection of Data in periodic intervals Stream Mode: Collect as and when the data is generated
Data Processing
- Bronze layer - Raw data after collecting from Source systems
- Silver Layer - Read data from Bronze layer, do required processing
- Gold Layer - preparing data for consumption, filling results into the desired data models
Azure Databricks Platform Architecture

Magic Commands
%sql
SELECT "Hello World" as msg
%fs
ls /tmp
%fs
# Run Linux shell commands
%scala
%md
# Header1 Markdown
%lsmagic
Databrics Utilities
dbutils.help()
credentials: DatabricksCredentialUtils -> Utilities for interacting with credentials within notebooks
data: DataUtils -> Utilities for understanding and interacting with datasets (EXPERIMENTAL)
fs: DbfsUtils -> Manipulates the Databricks filesystem (DBFS) from the console
jobs: JobsUtils -> Utilities for leveraging jobs features
library: LibraryUtils -> Utilities for session isolated libraries
meta: MetaUtils -> Methods to hook into the compiler (EXPERIMENTAL)
notebook: NotebookUtils -> Utilities for the control flow of a notebook (EXPERIMENTAL)
preview: Preview -> Utilities under preview category
secrets: SecretUtils -> Provides utilities for leveraging secrets within notebooks
widgets: WidgetsUtils -> Methods to create and get bound value of input widgets inside notebooks
Detailed documentation
dbutils.fs.help()